
Topic modelling with transcribed audio data
Reasearch question
Can topic labels for TED talk transcripts be generated in a data-driven way using Latent Dirichlet Allocation and exogenous reference texts?
Introduction
The amount of available audio data has been rising exponentially in the last decade, and with it, the need to process and manage it in an automatic way. Especially businesses see themselves confronted with a large amount of speech data that holds valuable information about their customers and products. One powerful tool that structures audio data in a meaningful way and has explicitly proven successful on audio transcripts is the Latent Dirichlet Allocation. It is used to decompose a collection of documents into latent topics that are syntactically similar. However, a common drawback of the Latent Dirichlet Allocation is that the latent topics are described as a distribution over words, instead of a simple descriptive name. This often requires human reviewing to characterize each created topic, which is subjective and labor-intensive. Prior research developed several approaches to overcome this interpretation issue, but until today, no established and automatic process generates a single label for a topic. In my thesis, a data-driven approach is proposed to automatically annotate topics and eventually transcripts with single labels using Latent Dirichlet Allocation and an exogenous reference corpus, on the example of TED talk transcripts.
Data
This research analysis is based on two text corpora. The main corpus, a collection of TED talk transcripts is available on Kaggle. The reference corpus, a collection of Wikipedia articles, was manually scraped from Wikipedia based on the topics available on the TED talk website.
Methods
An analysis consisting of three parts is conducted: first, the Latent Dirichlet Allocation is used to structure the underlying corpus into topics. In the second part of the analysis, a new, data-driven approach is explored to automatically label the created topics with a single topic tag to improve the interpretability of the topics and replace labor-intensive, human reviewing. Here, a created topic is compared to an exogenous reference corpus and labeled with the topic of the reference text based on the highest similarity. Two different methods for the comparison are tested (cosine similarity & the Wu & Palmer similarity measure). Finally, in the third part, documents are labeled with their most probable topic.
Main findings
Model accuracy
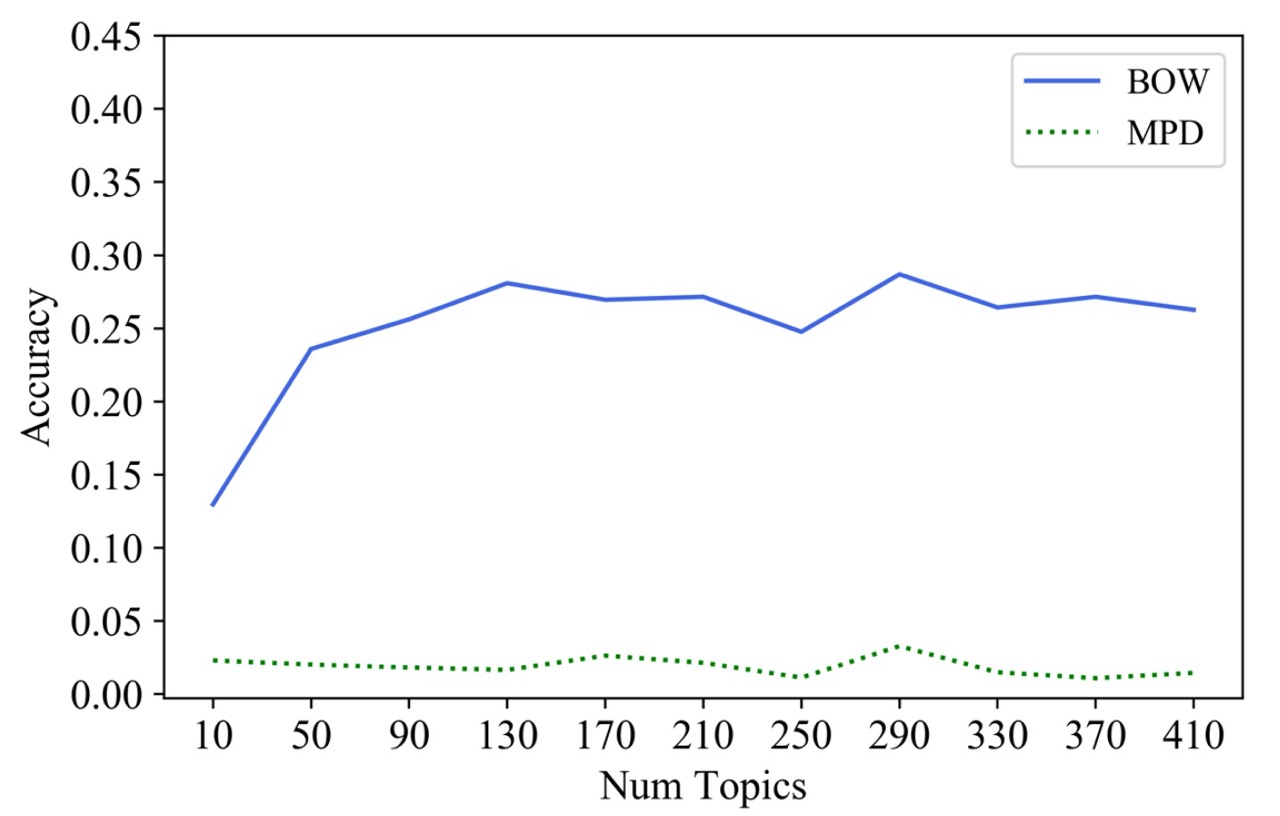
The results show that roughly 30% of the transcripts are labeled with a topic that matches one of the manual annotations of a transcript.
Prediction accuracy of correctly predicted documents using the bag-of-word (BOW) approach and the most probable documents (MPD) approach:
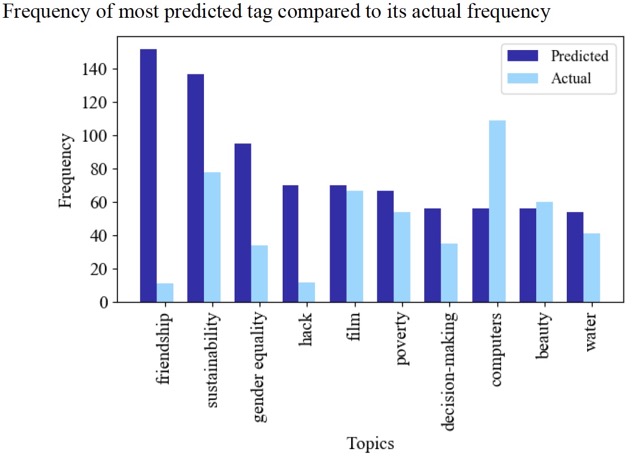
Frequency of most predicted tag compared to its actual frequency:
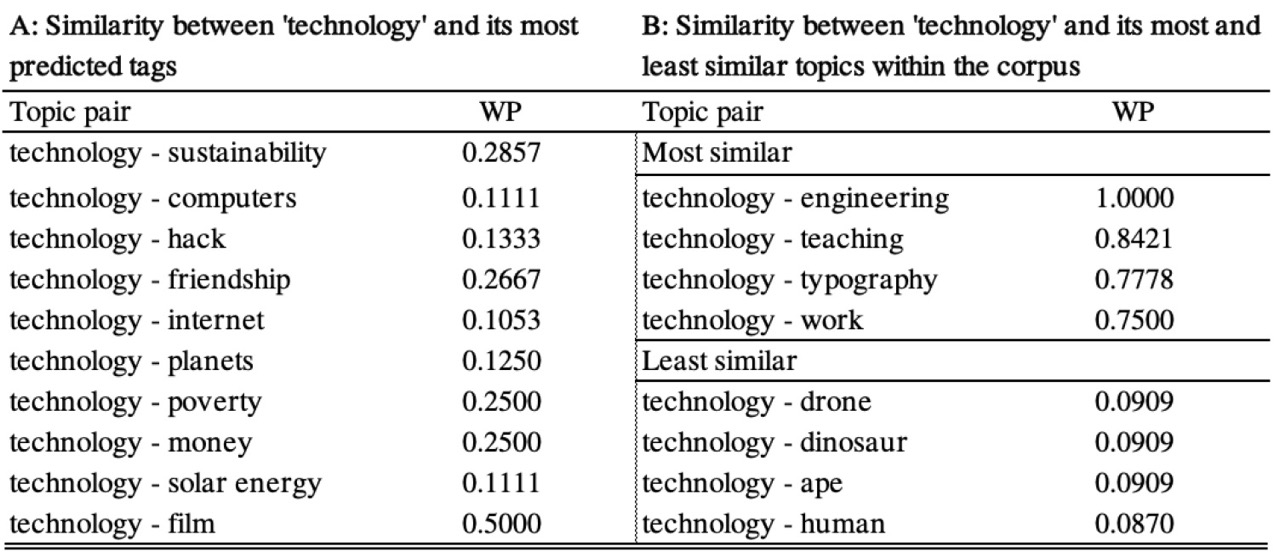
Semantic similarity analysis
The results from a semantic similarity analysis between predicted and actual labels further suggest that a small part of the discrepancy between data-driven and manual approach can be explained by the ambiguity in language.
The corresponding research paper is available on request.